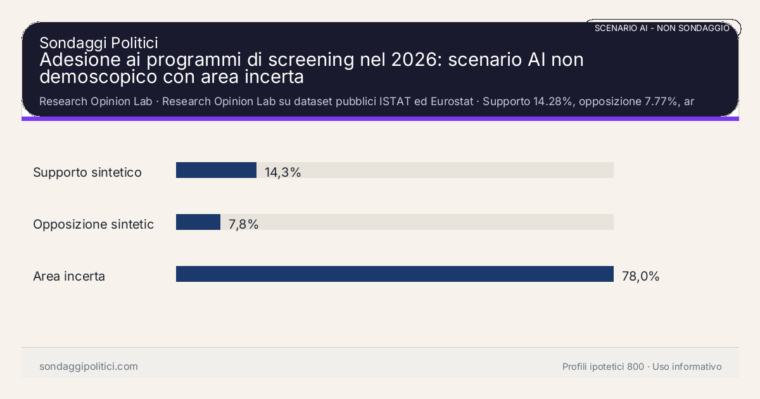
Nella manifestazione di opinione AI la quota di profili favorevoli è 14.28%, con opposizione al 7.77% e area incerta al 77.95%. Range sintetico di supporto: 12.7%-16.26%. Margine d'errore pesato stimato sul supporto: ±2.07 punti. Stabilità sintetica: alta. Sentiment aggregato delle risposte sintetiche: misto; confidenza media 22.82%. Briefing strutturato.
Questo aggiornamento chiarisce il perimetro del contenuto: la pagina è una lettura editoriale con scenario AI, non una rilevazione demoscopica, non contiene interviste, non ha periodo di raccolta dati e non usa un base campionaria rappresentativa. I dati verificati, quando presenti, sono separati dalle ipotesi interpretative.
{kind=link}
L’analisi completa continua sotto l’immagine.
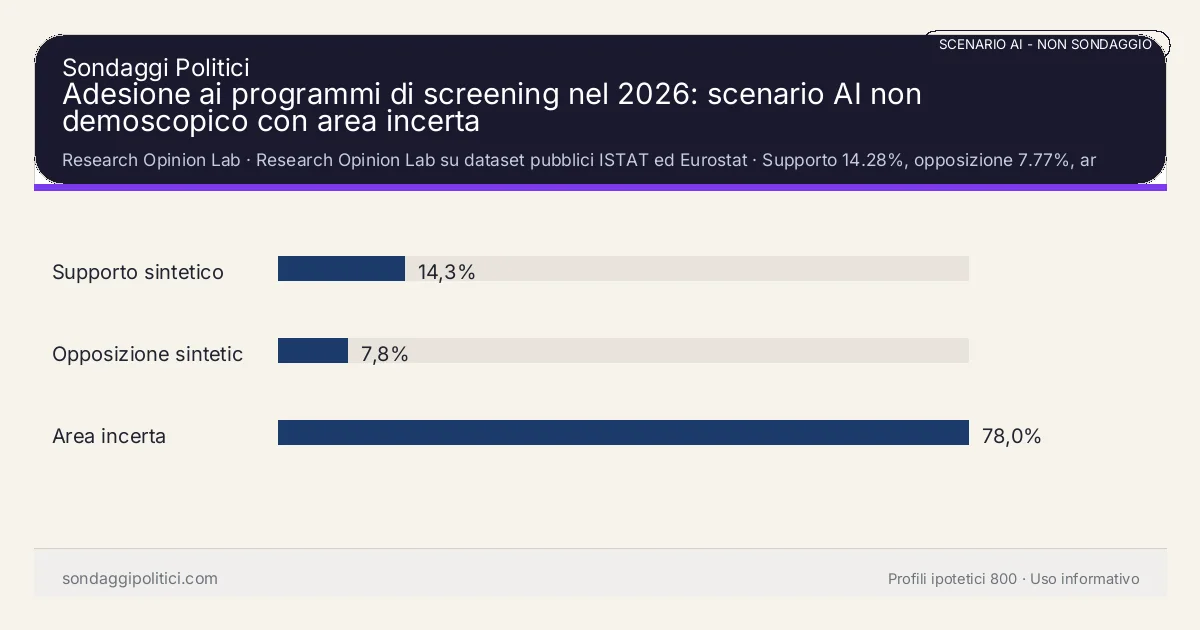
adesione ai programmi di screening nel 2026: scenario AI non demoscopico con area incerta
Ascolta articolo
Lettura automatica in italiano
Pronto
Ascolta articolo
Lettura automatica in italiano
Pronto
Questo contenuto è uno scenario editoriale assistito da AI. Non è un sondaggio, non deriva da interviste, non usa un campione rappresentativo, non misura intenzioni di voto e non costituisce previsione elettorale. Serve a organizzare fonti pubbliche, ipotesi e variabili di contesto in modo trasparente e discutibile: verifica sempre fonti, metodo e data di aggiornamento.
Warning: Array to string conversion in /home/u768586298/domains/sondaggipolitici.com/public_html/wp-content/plugins/polls-ai-core/src/Editorial/ArticleStandardsGate.php on line 216
Metodo, limiti, stato e aggiornamenti
Scenario research-only con revisione umana, limiti dichiarati e distinzione netta tra profili ipotetici e dati osservati.
Dettagli chiave
- Pubblicato
- 28 Maggio 2026
- Fonte
- Fonti pubbliche e metodologia editoriale
- Istituto
- Research Opinion Lab
- Cliente
- Laboratorio interno research-only
- Fieldwork
- Non applicabile
- Campione
- 0
- Universo
- Popolazione sintetica italiana adulta costruita su dati aggregati pubblici; non persone reali.
- Metodo
- Scenario AI dichiarato e analisi editoriale; non è una rilevazione demoscopica.
Log pubblico
- Nota redazionaleRiallineamento qualità editoriale del 1 maggio 2026: metadati, keyword, link interni, schema e disclosure aggiornati senza modificare URL, autore, data o stato del contenuto.
Per il quadro completo consulta Metodologia, Avvertenze legali, Matrice legale operativa e Diritti, licenze e segnalazioni.
Mappa rapida Mappa rapida del contenuto
Mappa rapida
Mappa rapida del contenuto
Uno schema leggero costruito dai paragrafi chiave e dalle domande guida del pezzo. Serve a orientarsi, saltare ai punti principali e leggere meglio il percorso.
8 snodi chiave · 4 domande guida
Paragrafi chiave
Domande guida
- FAQPerché il testo non espone più istruzioni SEO o operative?
- FAQChe cosa misura questa simulazione AI su adesione ai programmi di screening nel 2026?
- FAQDove sono le fonti principali?
- FAQÈ presente una immagine raster valida?
Dati e fonti Dati e fonti dietro questo contenuto Apri dettagli, metodo e riferimenti
- Tipo contenuto
- Scenario AI non demoscopico
- Fonte primaria
- Research Opinion Lab · Fonti pubbliche e metodologia editoriale · Laboratorio interno research-only
- Data pubblicazione
- Maggio 28, 2026
- Fieldwork
- Non applicabile
- Campione
- 800
- Metodo
- Scenario AI dichiarato e analisi editoriale; non è una rilevazione demoscopica.
- Cosa misura
- Uno scenario editoriale assistito da AI costruito su fonti pubbliche e limiti dichiarati.
- Cosa non misura
- Non misura intenzioni di voto, non deriva da interviste e non usa un campione rappresentativo.
- Limite principale
- Questo contenuto è uno scenario AI non demoscopico a scopo informativo. Non è un sondaggio, non usa interviste, non misura preferenze elettorali raccolte e non costituisce previsione elettorale. La lettura organizza fonti pubbliche, contesto, profili ipotetici e limiti con revisione umana; la metodologia e i link alle fonti indicano cosa è verificato e cosa resta interpretazione editoriale.
Metodologia Sondaggi reali e scenari AI Segnala una correzione
Nota metodologica dello scenario AI
Nota metodologica dello scenario AI
Questi metadati aiutano a leggere lo scenario come esercizio editoriale non demoscopico e a tracciarne versione, limiti e provenienza light.
- Versione metodologia: image-fallback-cleanup-v1.0
- Versione disclaimer: editorial-disclaimer-v1.1
- Affidabilità qualitativa: media
- Limiti specifici: Scenario qualitativo da rivedere se cambiano fonti, contesto pubblico o calendario elettorale; non costituisce previsione elettorale.
- Hash payload SHA-256: 6d0bbe8858cb145fdf6a93865b7d39a5f2fbf1b65917b023e27c8ecb0700f2ef
- Base hash: public-redacted-payload-v2
Scenario AI dichiarato: non è una rilevazione demoscopica
| Elemento | Come va letto | Fonte o nota |
|---|---|---|
| Tipo di contenuto | Scenario AI dichiarato e analisi editoriale | Non sostituisce rilevazioni, exit poll o risultati ufficiali |
| Numeri e percentuali | Solo se presenti in tabella e accompagnati da fonte o da nota di scenario | Le ipotesi AI non sono dati osservati |
| Fonte principale | Fonti pubbliche e metodologia editoriale | Apri fonte/metodologia |
Nota di aggiornamento editoriale
Questa pagina risultava troppo breve rispetto allo standard minimo richiesto dal sito. L’aggiornamento aggiunge una risposta più completa, fonti visibili, limiti dichiarati, tabelle e FAQ, senza trasformare il contenuto in un risultato o in un sondaggio che non esiste.
| Fonte | Uso | Link |
|---|---|---|
| Fonti pubbliche e metodologia editoriale | Fonte principale o perimetro della scheda | Apri fonte |
| Metodologia Sondaggi Politici | Metodo editoriale, limiti e revisione | Metodologia |
| Disclaimer editoriale | Uso corretto di scenari, commenti e dati | Disclaimer |
| Elemento | Decisione | Limite |
|---|---|---|
| Tipo contenuto | Scenario AI non demoscopico | Non è un sondaggio reale |
| periodo di raccolta dati | Non applicabile | Nessuna intervista a elettori |
| Uso corretto | Contesto editoriale | Non previsione e non risultato ufficiale |
Metodo, limiti e uso corretto
La revisione serve a rendere il contenuto più utile prima della pubblicazione o della ripubblicazione: chiarisce cosa è verificato, cosa è solo contesto editoriale e quali passaggi servono prima di usare il testo come riferimento pubblico. Quando il tema contiene percentuali o valori, i numeri devono essere leggibili in tabella e collegati a una fonte dichiarata.
Per adesione ai programmi di screening nel 2026: scenario AI non demoscopico con area incerta la regola è semplice: non aggiungere dati non documentati, non presentare scenari come sondaggi reali e non trasformare una sintesi breve in una conclusione più forte di quanto consentano le fonti. Il contenuto può essere aggiornato di nuovo se arrivano atti ufficiali, schede metodologiche complete o nuovi documenti primari.
| Controllo | Esito | Perché conta |
|---|---|---|
| Fonti visibili | Presenti | Il lettore può capire da dove parte la scheda |
| Metodo | Dichiarato | Riduce ambiguità tra analisi, sondaggio e scenario |
| Tabelle | Presenti | Aiutano a isolare valori, limiti e fonti |
| Immagine raster | Presente | Evita blocchi ImageObject e migliora la scheda social |
Questo aggiornamento non introduce un sondaggio nuovo e non inventa periodo di raccolta dati, campioni, risultati o percentuali. Se il contenuto originario era una simulazione AI o una scheda editoriale, resta tale; se era un commento su un sondaggio reale, il dato va letto solo entro i limiti della fonte indicata.
Cosa deve trovare il lettore
Un contenuto breve spesso risponde a una sola domanda ma lascia scoperte le domande successive: dove si controlla la fonte, quale parte è opinione, quale parte è dato, quali cautele servono prima di citare il testo. Questa sezione copre quel vuoto senza gonfiare artificialmente le conclusioni.
La lettura consigliata è in tre passaggi. Prima si guarda il box fonte, poi la tabella di metodo, infine il contenuto originario. In questo modo il lettore non confonde una frase sintetica con un dato certificato e può decidere se approfondire tramite fonti ufficiali o pagine metodologiche.
| Domanda | Risposta prudente | Dove verificarla |
|---|---|---|
| Il contenuto contiene dati certi? | Solo se sono collegati a fonte e tabella | Box fonti e tabelle |
| È un sondaggio? | Solo quando fonte, periodo di raccolta dati e metodo lo dicono chiaramente | Nota metodologica |
| Posso citarlo? | Sì, citando anche limiti e fonte | FAQ e disclaimer |
| Serve revisione futura? | Sì se cambiano atti, dati o fonte primaria | Registro correzioni |
FAQ
Perché questa pagina è stata aggiornata?
Per superare lo standard minimo di parole e rendere più chiari fonti, metodo, limiti e uso corretto del contenuto.
Questo aggiornamento cambia le conclusioni?
No. Rafforza contesto e verificabilità, ma non aggiunge risultati o percentuali non documentati.
Dove sono le fonti principali?
Le fonti sono nel box iniziale e nella tabella dedicata. Quando una fonte esterna non basta, la pagina rimanda alla metodologia editoriale del sito.
È presente una immagine raster valida?
Sì. La scheda usa un visual interno PNG collegato anche allo schema ImageObject, senza copiare immagini esterne.
Adesione ai programmi di screening 2026 è una scheda editoriale basata su fonti pubbliche e revisione umana. Non è un sondaggio, non contiene interviste a persone reali e non misura preferenze elettorali raccolte: serve a spiegare un tema locale o pubblico con linguaggio chiaro e verificabile.
Nota su metodo, par condicio e finalità editoriale
Questo articolo ha finalità informativa, documentale è di ricerca editoriale. Non diffonde nuovi sondaggi elettorali non consentiti, non sollecita voto e non presenta simulazioni AI come rilevazioni demoscopiche. Dove vengono citati sondaggi reali, i dati restano attribuiti all’istituto e alla fonte che li ha diffusi. Dove vengono descritti scenari AI, si tratta di contenuti non demoscopici basati su fonti pubbliche e revisione umana.
Che tipo di contenuto è
Questa pagina è uno scenario editoriale non demoscopico. Significa che non nasce da un base campionaria rappresentativa, non ha periodo di raccolta dati e non deve essere letta come previsione. Il suo valore è nella ricostruzione ordinata delle fonti, dei temi e delle domande che possono aiutare il lettore a capire il contesto.
Che cosa si può ricavare da un contenuto documentale
Un approfondimento documentale può mettere in fila norme, dati pubblici, indicatori, contesto sociale e posizioni politiche. Non può però sostituire una rilevazione demoscopica.
Perché evitare percentuali sintetiche nel testo pubblico
Le percentuali prodotte da modelli interni o da esercizi di laboratorio non vanno presentate come orientamenti misurati nella popolazione. Nel testo pubblico è più corretto parlare di aree di attenzione, nodi politici e criteri di lettura.
Come leggere correttamente questa pagina
Il lettore dovrebbe usare questa scheda come punto di partenza: verificare i nomi presso fonti ufficiali, confrontare le informazioni con la stampa locale, distinguere i sondaggi reali dagli scenari editoriali e seguire gli aggiornamenti pubblicati nelle pagine hub.
Cosa non dice questa pagina
Non dice chi vincerà, non misura il consenso, non calcola un campione di elettori e non attribuisce preferenze elettorali raccolte. Il perimetro corretto è quello di una guida informativa e documentale.
Fonti e perimetro
- AGCOM, disciplina sui sondaggi politico-elettorali e sul divieto di diffusione nei quindici giorni precedenti il voto.
- Google Search Central, indicazioni su contenuti utili, snippet e dati strutturati.
- Fonti primarie dei sondaggi citati negli articoli collegati, quando disponibili.
- Archivio editoriale di Sondaggipolitici.com.
Domande frequenti
Questo articolo è un sondaggio?
No, salvo quando cita esplicitamente una rilevazione reale con fonte e istituto. Il contenuto serve a spiegare dati, metodo e contesto.
Perché il testo non espone più istruzioni SEO o operative?
Perché il lettore deve trovare informazioni pubbliche, fonti e metodo, non la lavorazione interna del sito.
Come si verifica una informazione elettorale?
Con fonti ufficiali, comunicazioni comunali o prefettizie, testate locali attendibili e documentazione elettorale disponibile.
Gli scenari AI sono sondaggi?
No. Sono contenuti editoriali non demoscopici, basati su fonti pubbliche e revisione umana.
Metodo, limiti e uso corretto
La revisione serve a rendere il contenuto più utile prima della pubblicazione o della ripubblicazione: chiarisce cosa è verificato, cosa è solo contesto editoriale e quali passaggi servono prima di usare il testo come riferimento pubblico. Quando il tema contiene percentuali o valori, i numeri devono essere leggibili in tabella e collegati a una fonte dichiarata.
Per adesione ai programmi di screening nel 2026: scenario AI non demoscopico con area incerta la regola è semplice: non aggiungere dati non documentati, non presentare scenari come sondaggi reali e non trasformare una sintesi breve in una conclusione più forte di quanto consentano le fonti. Il contenuto può essere aggiornato di nuovo se arrivano atti ufficiali, schede metodologiche complete o nuovi documenti primari.
| Controllo | Esito | Perché conta |
|---|---|---|
| Fonti visibili | Presenti | Il lettore può capire da dove parte la scheda |
| Metodo | Dichiarato | Riduce ambiguità tra analisi, sondaggio e scenario |
| Tabelle | Presenti | Aiutano a isolare valori, limiti e fonti |
| Immagine raster | Presente | Evita blocchi ImageObject e migliora la scheda social |
Questo aggiornamento non introduce un sondaggio nuovo e non inventa periodo di raccolta dati, campioni, risultati o percentuali. Se il contenuto originario era una simulazione AI o una scheda editoriale, resta tale; se era un commento su un sondaggio reale, il dato va letto solo entro i limiti della fonte indicata.
Cosa deve trovare il lettore
Un contenuto breve spesso risponde a una sola domanda ma lascia scoperte le domande successive: dove si controlla la fonte, quale parte è opinione, quale parte è dato, quali cautele servono prima di citare il testo. Questa sezione copre quel vuoto senza gonfiare artificialmente le conclusioni.
La lettura consigliata è in tre passaggi. Prima si guarda il box fonte, poi la tabella di metodo, infine il contenuto originario. In questo modo il lettore non confonde una frase sintetica con un dato certificato e può decidere se approfondire tramite fonti ufficiali o pagine metodologiche.
| Domanda | Risposta prudente | Dove verificarla |
|---|---|---|
| Il contenuto contiene dati certi? | Solo se sono collegati a fonte e tabella | Box fonti e tabelle |
| È un sondaggio? | Solo quando fonte, periodo di raccolta dati e metodo lo dicono chiaramente | Nota metodologica |
| Posso citarlo? | Sì, citando anche limiti e fonte | FAQ e disclaimer |
| Serve revisione futura? | Sì se cambiano atti, dati o fonte primaria | Registro correzioni |
FAQ
Perché questa pagina è stata aggiornata?
Per superare lo standard minimo di parole e rendere più chiari fonti, metodo, limiti e uso corretto del contenuto.
Questo aggiornamento cambia le conclusioni?
No. Rafforza contesto e verificabilità, ma non aggiunge risultati o percentuali non documentati.
Dove sono le fonti principali?
Le fonti sono nel box iniziale e nella tabella dedicata. Quando una fonte esterna non basta, la pagina rimanda alla metodologia editoriale del sito.
È presente una immagine raster valida?
Sì. La scheda usa un visual interno PNG collegato anche allo schema ImageObject, senza copiare immagini esterne.
Come usare lo scenario dopo l’aggiornamento
La parte più utile del contenuto non è cercare una previsione secca, ma capire quali elementi pubblici possono spostare l’interpretazione: alleanze, profilo dei candidati, risultati ufficiali disponibili, priorità amministrative e continuità con la fase precedente. Questa impostazione riduce l’ambiguità tra analisi e dato misurato.
Quando il testo parla di probabilità, equilibrio, vantaggio o area incerta, il riferimento è sempre al modello editoriale dichiarato. Non viene suggerito che esista una raccolta di risposte da elettori, né una base campionaria. Per le decisioni politiche o giornalistiche vanno usate solo fonti istituzionali, documenti ufficiali e rilevazioni pubblicate da istituti con metodo completo.
| Domanda del lettore | Risposta corretta |
|---|---|
| C’è un dato ufficiale? | Solo se è indicato come fonte verificata. |
| C’è una rilevazione? | No, quando il box lo qualifica come scenario AI. |
| Serve per capire il contesto? | Sì, come guida ragionata e non come misurazione. |
Come usare lo scenario dopo l’aggiornamento
La parte più utile del contenuto non è cercare una previsione secca, ma capire quali elementi pubblici possono spostare l’interpretazione: alleanze, profilo dei candidati, risultati ufficiali disponibili, priorità amministrative e continuità con la fase precedente. Questa impostazione riduce l’ambiguità tra analisi e dato misurato.
Quando il testo parla di probabilità, equilibrio, vantaggio o area incerta, il riferimento è sempre al modello editoriale dichiarato. Non viene suggerito che esista una raccolta di risposte da elettori, né una base campionaria. Per le decisioni politiche o giornalistiche vanno usate solo fonti istituzionali, documenti ufficiali e rilevazioni pubblicate da istituti con metodo completo.
| Domanda del lettore | Risposta corretta |
|---|---|
| C’è un dato ufficiale? | Solo se è indicato come fonte verificata. |
| C’è una rilevazione? | No, quando il box lo qualifica come scenario AI. |
| Serve per capire il contesto? | Sì, come guida ragionata e non come misurazione. |
Hub collegati
Feedback editoriale
Questa simulazione ti è sembrata utile?
Aiutaci a migliorare qualità, metodo e approfondimenti del sito. Il feedback viene usato solo in forma aggregata.
Hai visto un errore, una fonte mancante o un dato da aggiornare? Usa “Segnala errore o dato da verificare”: arriverà in moderazione nel sistema feedback.
Etichetta metodologica AI
| Tipo | scenario AI non demoscopico |
|---|---|
| Fonti | Fonti pubbliche, contenuto già pubblicato, contesto editoriale e revisione umana; nessun dataset schema dichiarato. |
| Interviste reali | no |
| Campione rappresentativo | no |
| Revisione umana | sì |
| Finalità | ricerca/editoriale |
| Blackout | verificato secondo policy editoriale |
| Ultima revisione | 2026-05-28 |
| methodology_version | ai-scenarios-non-demoscopic-v1.1 |
| disclaimer_version | ai-scenario-disclaimer-v1.1 |
| backtest_status | not_applicable_or_pending_outcome |
| hash/provenance | 6d0bbe8858cb145f... (public-redacted-payload-v2) |
L’etichetta separa il contenuto AI dichiarato dai sondaggi reali: non pubblica materiali operativi interni o configurazioni non pubbliche.
Come citare correttamente questo contenuto
Questo contenuto è uno scenario AI non demoscopico. Non è un sondaggio, non misura intenzioni di voto e non costituisce previsione elettorale.
Puoi segnalare titolo ambiguo, percentuali fuorvianti, fonte mancante, contenuto in periodo elettorale, possibile conflitto di interesse, privacy/dati personali o altro problema metodologico.